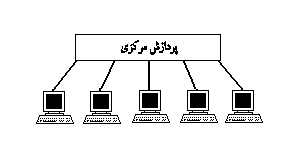
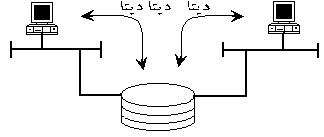
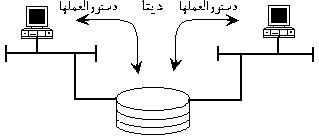
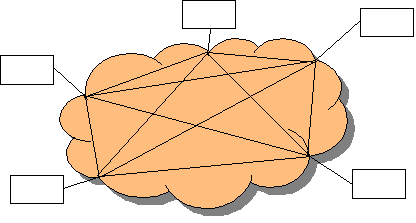
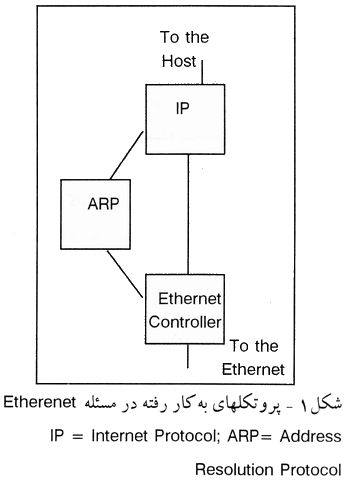
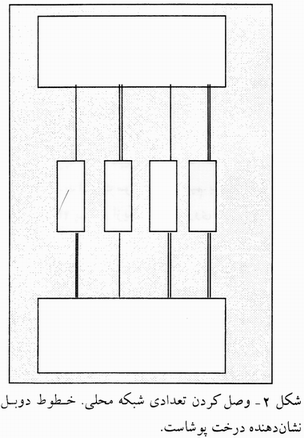
از آنگاه
كه انسان پا در كره خاكي نهاد، همواره زمان و مكان دو
پارامتري بودند كه او را به خود محصور كرده، و اگرچه وجود
اين دو پارامتر به زندگي انسان معني ميداد و داستان زندگي
بشر در گذشت زمان و تغيير مكان تعريف ميشد، با اين وجود
دو عامل محدودكننده زمان و مكان بر وجود بشر سنگيني
ميكرده است.
آيا تا به
حال اتفاق افتاده كه در يك ساعت خاص جلسه مهمي داشته باشيد
و يك ساعت قبل از شروع جلسه در مسير رسيدن به آن با ترافيك
سنگيني برخورد كرده باشيد؟ در اين ترافيك سنگين گذشت زمان
حتي دقايق و ثانيههاي آن براي شما رنجآور خواهد بود و
خود را اسير مكان ميبينيد طوري كه نميتوانيد طومار معني
آن را درهم بپيچيد و در مكان مورد نظر حاضر شويد.
همانطور
كه اشاره شد زمان و مكان، داستان زندگي ما را پايهگذاري
ميكنند. اما اين دو پيش از آنكه براي بشر مفيد جلوه كنند،
بيشتر آثار بازدارنده خود را به رخ ميكشند. در نتيجه
انسان آگاهانه يا ناخودآگاه همواره در صدد غلبه بر اين دو
عامل بازدارنده بوده است.
ساخت
وسائط نقليه ابتدايي، اولينگام براي غلبه بر مكان بود و
از زماني كه پيشرفت اين وسائط جهت دستيابي به سرعت بالاتر
و كاستن زمان لازم براي تغيير مكان آغاز شد، انسان براي
غلبه بر زمان نيز گام نخست را برداشت. تا آنجا كه در
داستانهاي تخيلي بشر 50 سال پيش مي توان به اتومبيلها و
توربوترنهاي فوق سريع برخورد كه كره خاكي را تحت سيطره او
در ميآورد. با توجه به خودروهاي فوق سريع در تخيل بشر 50
سال پيش، زندگي 50 سال آينده تصوير زيبايي مييابد. زندگي
50 سال آينده تغيير بسيار زيادي را شاهد خواهد بود زيرا او
از بند زمان و مكان خواهدرست. ديگر شما مجبور نخواهيد بود
منزل خود را نزديك به محل كار خود انتخاب نماييد، به راحتي
ميتوانيد در يك مكان خوش آب و هوا و مطابق ميل خود اقامت
كنيد و فقط چند دقيقه قبل از زمان شروع كار خود از منزل
خارج شويد و توسط يكي از اين توربوترنهاي فوق سريع در
زمان مناسب در محل كار خود حاضر شويد. در اين دنياي تخيلي
شهرها معناي خود را از دست ميدهند و انسانها در زمين
پراكنده ميشوند.
اين دنياي
زيبا در تخيل بشر 50 سال پيش توسط توربوترنها و وسائط
نقليه فوق سريع دست يافتني بود، تا اينكه بحث ارتباطات و
شبكههاي كامپيوتري گام به عرصه دنياي تكنولوژي نهاد.
شبكههاي
كامپيوتري جهاني (كه انسانهاي مختلف با آداب و رسوم مختلف
در دورترين نقاط جهان را به يكديگرمرتبط ميسازند) زودتر
از آنچه كه فكرش را بكنيم روياي بشر را به تحقق رساندند.
در دنياي شبكههاي كامپيوتري جهاني براي ديدن دوستان خود و
بحث و تبادل نظر پيرامون مسائل مختلف، ديگر نيازي به تغيير
مكان و يا زمان خود نداريد، ميتوانيد به راحتي در هر لحظه
دلخواه و در كمتر از چند ثانيه به دوستي در آنسوي جهان
دسترسي داشته باشيد و اطلاعات لازم را از او گرفته و يا
اطلاعات مورد نيازش را به او برسانيد.
شايد اين
سئوال براي شما به وجود آمده باشد كه چگونه شبكههاي
كامپيوتري در عرصه تكنولوژي حضور يافتند؟
بشر اوليه
از آغاز به اين امر واقف بود كه براي ادامه حيات نياز به
ارتباط با ديگر انسانها دارد و اولين گام را (ۿا ايجاد
صداهاي مختلف زباني و يا كشيدن خطوط مختلف بر سنگها برداشت
و براي رساندن پيام خود به دور دست استفاده از دود آتش را
تجربه كرد. با پيشرفت بشر و به وجود آمدن تفنگها و توپها
استفاده از آنها نيز براي رساندن پيام براي او مفيد واقع
شد. در دنياي تكنولوژيك و پيشرفته قرن اخير، پست ، تلگراف
و تلفن ادامه مسيري هستند كه بشر نخستين آغاز نمود.
اما
محدوديتها و قدرت اندك وسائل ارتباطي مانند پست، تلگراف و
تلفنهاي اوليه، دانشمندان را بر آن داشت كه همين وسايل
ارتباطي را نيز پيشرفتهتر كنند. معايب اين سيستمها را مي
توان به صورت زير برشمرد:
رسيدن دير
هنگام محمولـههاي پستي و گاه مفقود شدن آنها از مهمترين
معايب پست بشمار ميآيند. در دنيايي كه تجارت و اقتصاد،
در لحظه تعيين موقعيت ميشوند ديگر نميتوان بستهاي پستي
را از مبدأ فرستاد و يك هفته بعد در مقصد آن را دريافت
نمود. تلگراف و عدم توانايي آن در ارسال تصاوير، ديتاي خاص
و اطلاعات با حجم بالا نيز نتوانست نياز بشر را جبران
نمايد. آنگاه كه تلفن توانست بدون داشتن محدوديتهاي پست و
تلگراف در اختيار بشر قرار گيرد، ديگر پيشرفت دنياي حاضر
آن قدر بود كه خواستههاي او را افزايش دهد و تلفن هم
نتواند جوابگوي نيازهاي او باشد. اختلاف ساعات شبانه روز
در مدارهاي مختلف زمين و محدوديتهاي زماني و مكاني ديگر
را مي توان از علل عدم كارايي تلفن براي بشر امروز
برشمرد. به عنوان مثال شما در طول شبانه روز شايد فقط 10
ساعت در منزل باشيد، كه از اين 10 ساعت نيز 6 تا 8 ساعت آن
را در خواب به سر ميبريد و تلفن منزل شما عملاً كارايي
لازم را ندارد. تعدد مشاغل و پيچيدگي شغلي بشر امروز نيز
به گونهاي است كه كمتر كسي در يك محل ثابت و مشخص مشغول
به كار است بنابراين تلفن محل كار نيز اعتبار خود را از
دست ميدهد.
اين
مشكلات باعث به صحنه آمدن تلفن همراه گرديد. اما تلفنهاي
همراه نيز نتوانست بعضي محدوديتهاي تلفنهاي ثابت را بر
طرف نمايد. تا آنكه شبكههاي جهاني با داشتن قابليتهاي
بسيار زياد پا به عرصه زندگي بشر نهادند و هم اكنون شما
ميتوانيد به راحتي با دورترين نقاط جهان ارتباط برقرار
كنيد و هر نوع ارتباط كه مد نظر شما باشد توسط اين
شبكههاي جهاني ميسر است.پست الكترونيكي با قابليتهاي
بسيار زياد بدون داشتن هيچ گونه محدوديت زماني، مكاني و يا
محدوديت در نوع ديتاي ارسالي ميتواند هر نوع نقل و
انتقالات اطلاعات شما را پاسخ دهد.
ديگر براي
شركت در جلسات و حضور بهم رساندن با دوستان يا دانشجويان
خود نيازي نيست به محل خاصي نقل مكان كنيد. شما ميتوانيد
در منزل خود باشيد و با دوستان خود كه ممكن است هر يك در
گوشهاي از زمين باشند تشكيل جلسه داده، با يكديگر به بحث
و تبادل نظر بپردازيد. اين بحث و تبادل نظر مي تواند به
صورت متن، تصوير و صدا باشد.
ديگر
نيازي نيست براي معرفي شركت، كارخانه و يا تبليغ براي
محصولات خود كاتالوگهايي را تهيه نماييد و به ديگر نقاط
جهان ارسال كنيد. به راحتي مي توانيد اطلاعات خود را بر
روي شبكه جهاني قرار داده تا هر كسي كه مي خواهد از آنها
استفاده نمايد. همچنين شما مي توانيد در شركتها،
فروشگاهها، دانشگاهها و مراكز تحقيقات جهاني به راحتي
جستجو كنيد و اطلاعات مورد نياز خود را بيابيد.
در اين
كتاب ضمن بررسي مباني شبكههاي كامپيوتري و ارائه روشهاي
مختلف جهت ارتباط كامپيوترهاي گسترشيافته در محدودههاي
كوچك و بزرگ، به روشهاي كاربردي استفاده از شبكههاي
كامپيوتري پرداخته و نحوه استفاده از سرويسهاي مختلف
شبكههاي جهاني مانند اينترنت را به صورت تفصيلي بررسي
مينماييم.